
Introduction
This project is an excerpt from a seminar conducted by Ayush Thakur, a prominent Machine Learning Engineer at Weights & Biases, and Maxim Voisin, a Senior Product Manager at Cohere.
They present a trailer for their upcoming full course titled "RAG++: Taking Your RAG Beyond Proof of Concept (POC)", in collaboration with Weaviate.
If you're unfamiliar with RAG (Retrieval-Augmented Generation), don't worry—we'll explore it throughout this course.
The project is composed of two parts.
Table of Contents
- 4.1 Simple RAG
- i. Limitation 1: Limited Chunk-Based Understanding
- ii. Limitation 2: Difficulty Comparing Information from Multiple Documents
- iii. Limitation 3: Analyzing Complex Data
- iv. Limitation 4: Struggles with Complex Questions
- 4.2 Agentic RAG
- Agentic RAG Definition
- Agentic RAG Use Case
- Demo: Putting It All Together
- Part 2: RAG with Use of Cohere and Weaviate
- References
Introduction
Project Overview
This project is an excerpt from a seminar conducted by Ayush Thakur, a prominent Machine Learning Engineer at Weights & Biases, and Maxim Voisin, a Senior Product Manager at Cohere.
Upcoming Full Course
They present a trailer for their upcoming full course titled "RAG++: Taking Your RAG Beyond Proof of Concept (POC)", in collaboration with Weaviate.
Familiarity with RAG
If you're unfamiliar with RAG (Retrieval-Augmented Generation), don't worry—we'll explore it throughout this course.
Project Composition
The project is composed of two parts.
Part 1: Flexible RAG: Development and Evaluation Strategies
1. What is RAG?
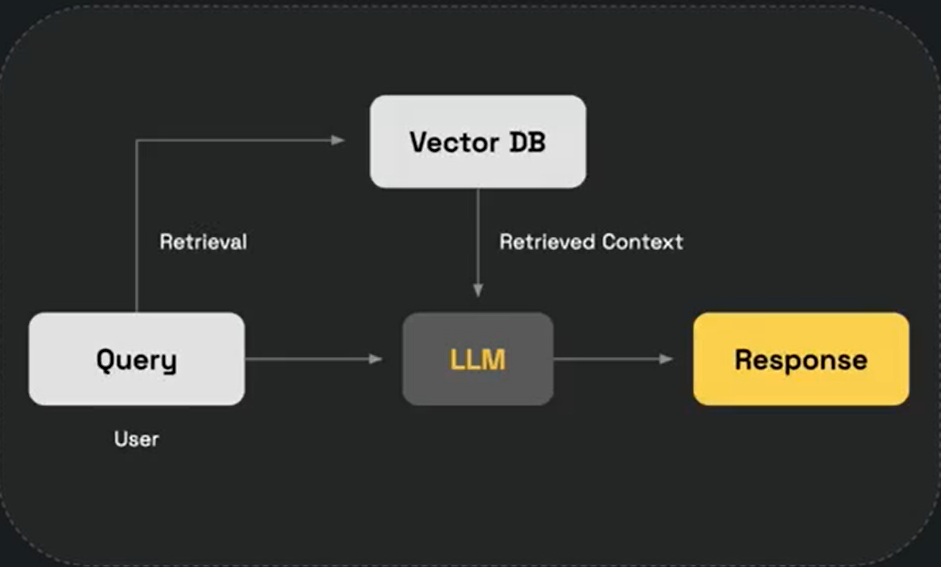
RAG, short for Retrieval-Augmented Generation, works by integrating retrieval-based techniques with generative-based AI models. Retrieval-based models excel at extracting information from pre-existing online sources like newspaper articles, databases, blogs, and other knowledge repositories such as Wikipedia or even internal databases. However, such models cannot produce original or unique responses. Alternatively, generative models can generate original responses that are appropriate within the context of what is being asked, but can find it difficult to maintain strict accuracy. To overcome these relative weaknesses in existing models, RAG was developed to combine their respective strengths and minimize their drawbacks. In a RAG-based AI system, a retrieval model is used to find relevant information from existing information sources while the generative model takes the retrieved information, synthesizes all the data, and shapes it into a coherent and contextually appropriate response.
2. Benefits of RAG
By integrating retrieval and generative artificial intelligence (AI) models, RAG delivers responses that are more accurate, relevant, and original while also sounding like they came from humans. That’s because RAG models can understand the context of queries and generate fresh and unique replies by combining the best of both models. By doing this, RAG models are:
2.1 More Accurate
By first using a retrieval model to identify relevant information from existing knowledge sources, the original human-like responses that are subsequently generated are based on more relevant and up-to-date information than a pure generative model.
2.2 Better at Synthesizing Information
By combining retrieval and generative models, RAG can synthesize information from numerous sources and generate fresh responses in a human-like way. This is particularly helpful for more complex queries that require integrating information from multiple sources.
2.3 Adept at Putting Information into Context
Unlike simple retrieval models, RAG can generate responses that are aware of the context of a conversation, and are thus more relevant.
2.4 Easier to Train
Training an NLP-based large language model (LLM) to build a generative AI model requires a tremendous volume of data. Alternatively, RAG models use pre-existing and pre-retrieved knowledge sources, reducing the need to find and ingest massive amounts of training data.
2.5 More Efficient
RAG models can be more efficient than large-scale generative models, as the initial retrieval phase narrows down the context and thus the volume of data that needs to be processed in the generation phase.
3. How is RAG Being Used Today?
These are some real-life examples of how RAG models are being used today to:
3.1 Improve Customer Support
RAG can be used to build advanced chatbots or virtual assistants that deliver more personalized and accurate responses to customer queries. This can lead to faster responses, increased operational efficiencies, and eventually, greater customer satisfaction with support experiences.
3.2 Generate Content
RAG can help businesses produce blog posts, articles, product catalogs, or other content by combining its generative capabilities with retrieving information from reliable sources, both external and internal.
3.3 Perform Market Research
By gathering insights from the vast volumes of data available on the internet—such as breaking news, industry research reports, even social media posts—RAG can keep businesses updated on market trends and even analyze competitors’ activities, helping businesses make better decisions.
3.4 Support Sales
RAG can serve as a virtual sales assistant, answering customers’ questions about items in inventory, retrieving product specifications, explaining operating instructions, and in general, assisting in the purchasing lifecycle. By marrying its generative abilities with product catalogs, pricing information, and other data—even customer reviews on social media—RAG can offer personalized recommendations, address customers’ concerns, and improve shopping experiences.
3.5 Improve Employee Experience
RAG can help employees create and share a centralized repository of expert knowledge. By integrating with internal databases and documents, RAG can give employees accurate answers to questions about company operations, benefits, processes, culture, organizational structure, and more.
4. Types of RAGs
4.1 Simple RAG
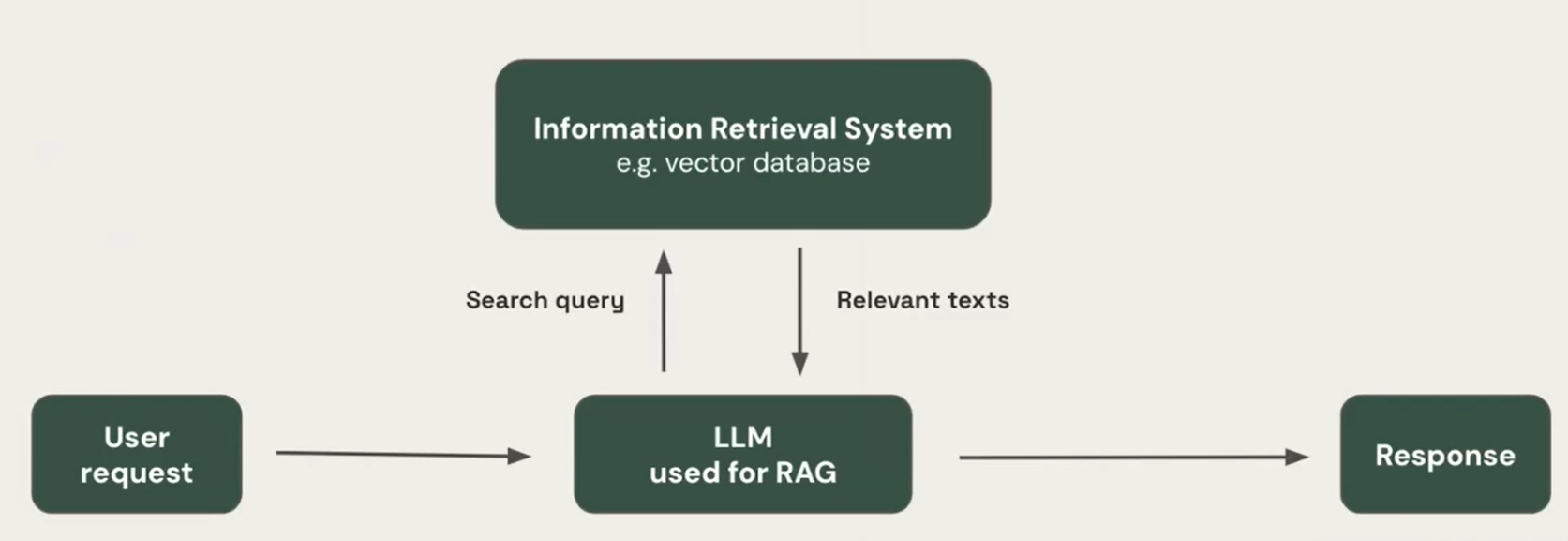
Simple RAG systems have inherent limitations:
i. Limitation 1: Limited Chunk-Based Understanding
Simple RAG systems struggle when the answer isn't confined to just a few chunks or requires understanding the document as a whole.
Examples:
- Summarization
- User Query: Summarize the key points from Nvidia's latest quarterly earnings report.
- Comprehensive Understanding of the Document
- User Query: How does Google's letter to shareholders reflect their mission of improving the lives of as many people as possible?
ii. Limitation 2: Difficulty Comparing Information from Multiple Documents
Simple RAG systems struggle when the answer requires comparing information from multiple documents.
Example:
- Cross-Analysis
- User Query: Compare the AI strategies of Google and Microsoft based on these two reports.
iii. Limitation 3: Analyzing Complex Data
Simple RAG systems struggle when the answer requires analyzing complex data.
Examples:
- Chat with Spreadsheet or Tabular Data
- User Query: From the given table, what is the average sales volume for our top 3 products?
- Chat with SaaS Apps
- User Query: How did our customer churn rate change in the last 3 months?
iv. Limitation 4: Struggles with Complex Questions
Simple RAG systems struggle with complex questions, especially those that require multiple steps to answer or involve multiple document references.
Example:
- Multi-Step Reasoning
- User Query: From this report, which city in Europe would be the best location for our next conference, taking into account the number of attendees, travel costs, and availability of venues?
Now to overcome some of these limitations, we can use a Flexible RAG,
i. For multi-part questions use Parallel Queries:
User Query: What's the number of employees of Nvidia, Microsoft and Google?

ii. For Complex data types, use RAG with Tools:
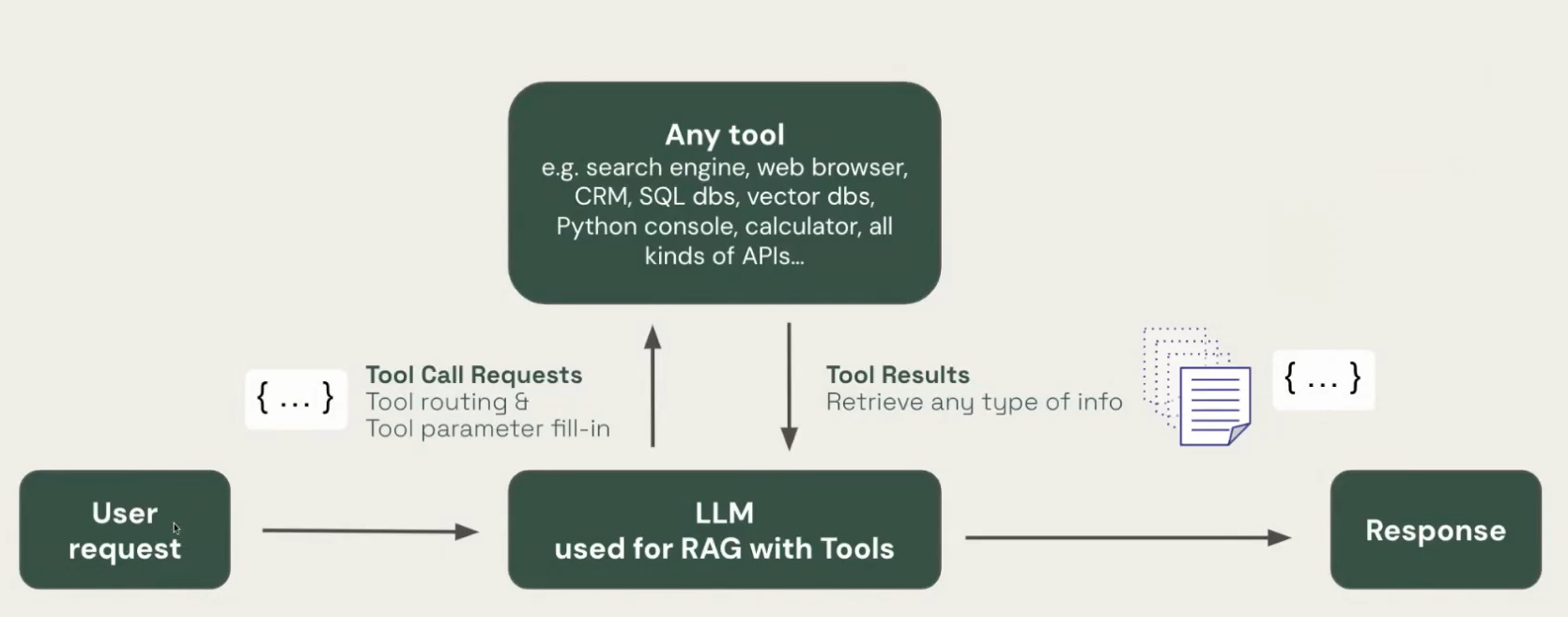
User Query 1: From the given table, what is the average sales volume for our top 3 products? User Query 2: How did our customer churn rate change in the last 3 months?
Instead of always retrieving from a vector db, allow the model to retrieve from any tool.
- retrieve from spreadsheets, using a Python console
- retrieve from the internet, using a search engine
- retrieve from any SaaS app, like a CRM, using APIs
- retrieve from SQL databases, using a code interpreter(e.g. python interpreter for .csv files)
For Sequential Reasoning, use Agentic RAG, now let's explore what Agentic RAG is in more details.
4.2 Agentic RAG
Agentic RAG Definition
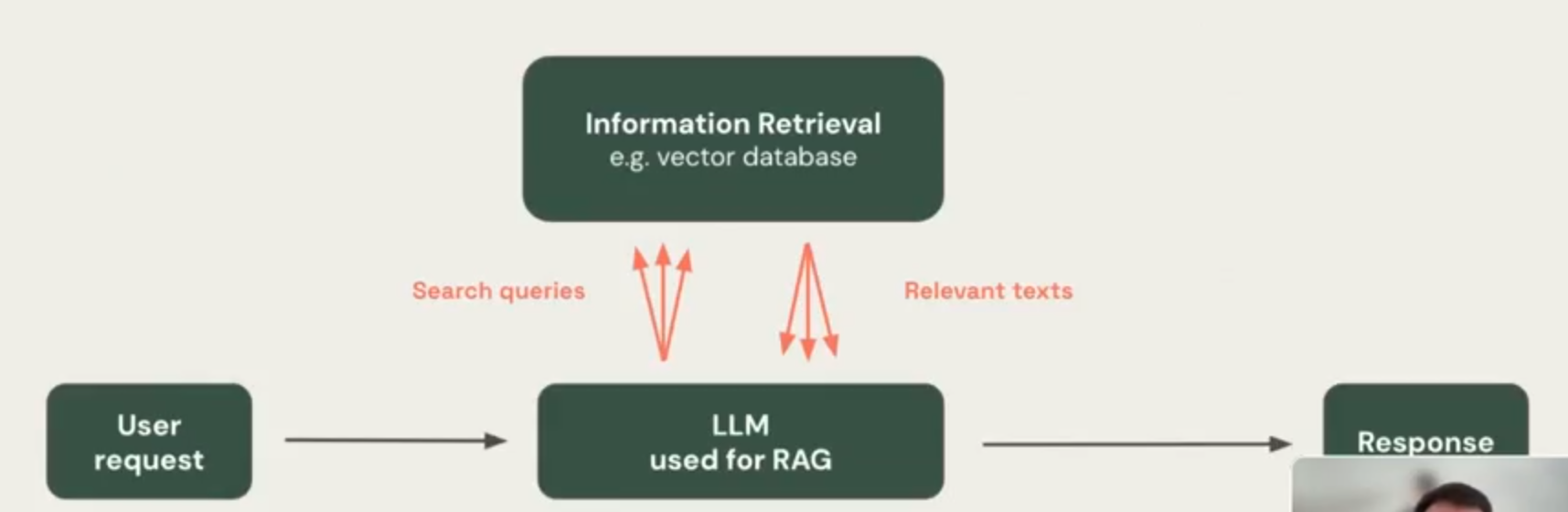 Agentic RAG can process more complex queries, compare data across multiple documents, and perform multi-step reasoning, making it an ideal solution for more advanced and complicated use cases.
Agentic RAG = RAG with Tools + PLAN
Agentic RAG can process more complex queries, compare data across multiple documents, and perform multi-step reasoning, making it an ideal solution for more advanced and complicated use cases.
Agentic RAG = RAG with Tools + PLAN
Agentic RAG Use Case
Agentic RAG is ideal for businesses that need to conduct comprehensive research, draw insights from complex data, or perform multi-step reasoning to make informed decisions.
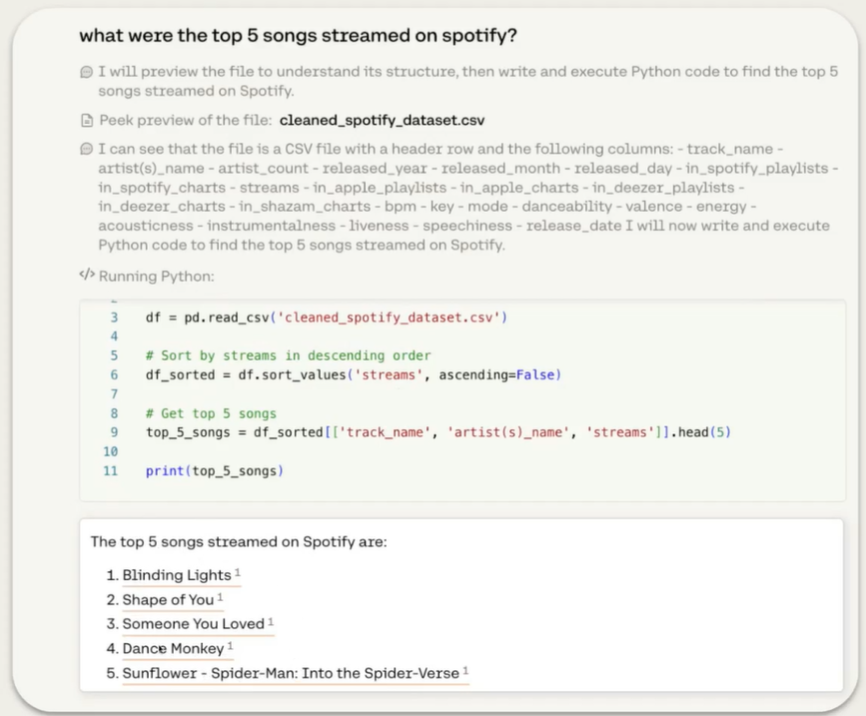
Demo: Putting It All Together
In this section, you'll find a comprehensive demo showcasing Agentic RAG at work, demonstrating how it tackles a complex query that requires advanced reasoning and data comparison from multiple sources.
Part 2: RAG with Use of Cohere and Weaviate
In this part of the project, we'll delve into how you can build a RAG system using Cohere with Integration of Waive. We'll walk through the steps of integrating these tools, building your own retrieval-augmented generation system, and optimizing it for different business use cases.
1. What is Weave?
Weave is a lightweight toolkit for tracking and evaluating LLM applications, built by Weights & Biases.
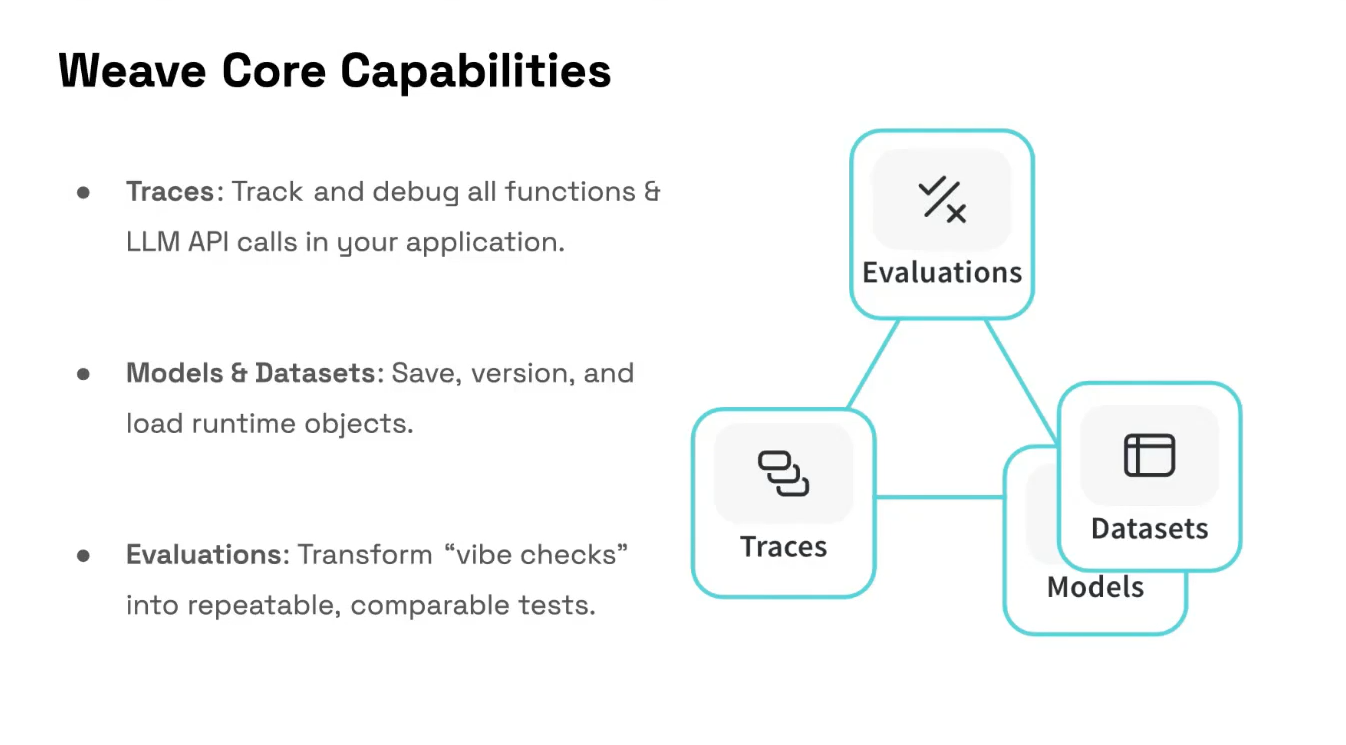
2. Benefits of Using Weave in Model Developments
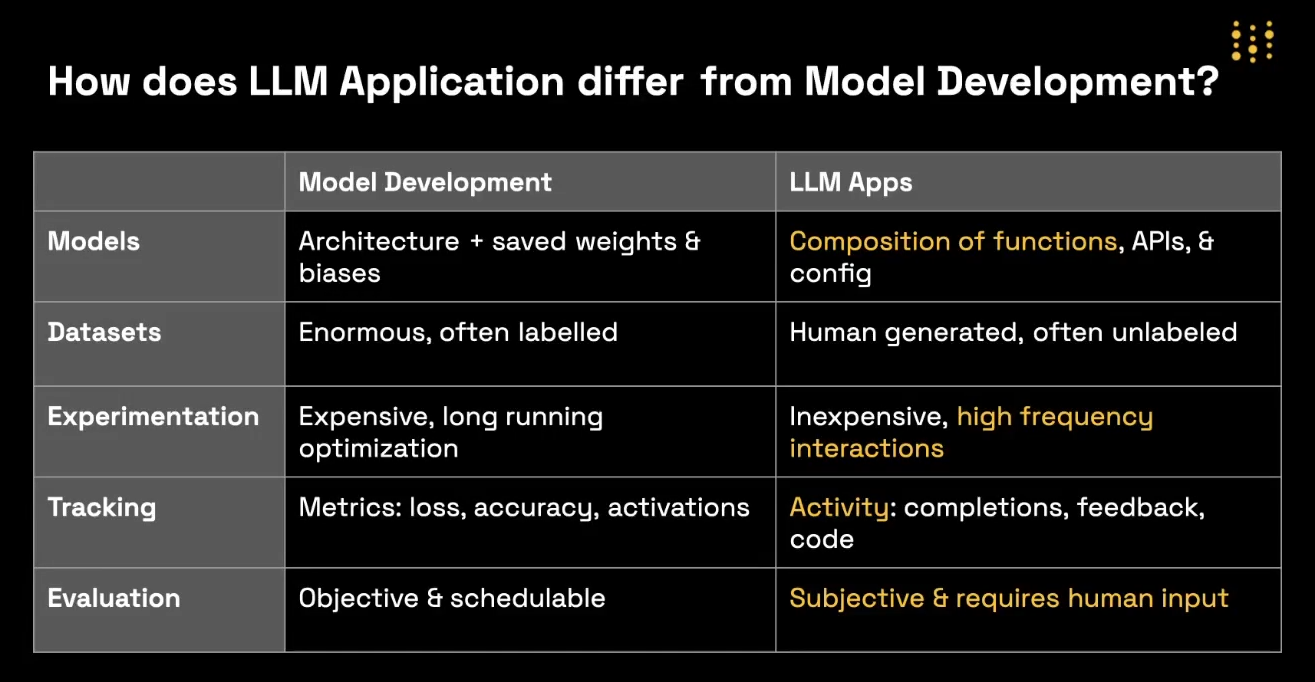
2.1. More Accurate
Weave-based systems can better integrate real-world knowledge, improving model predictions.
2.2. Better at Synthesizing Information
Weave combines various external data streams, making it better at synthesizing and generating accurate results.
2.3. Adept at Putting Information into Context
Weave’s ability to pull context-specific information helps in delivering more relevant results.
2.4. Easier to Train
Weave reduces the training complexity by focusing on retrieval-enhanced learning, minimizing the need for exhaustive dataset training.
2.5. More Efficient
Weave’s design allows for the streamlined development of AI models, improving efficiency at scale.
3. Comparison between Weave LLM and Traditional Model Development
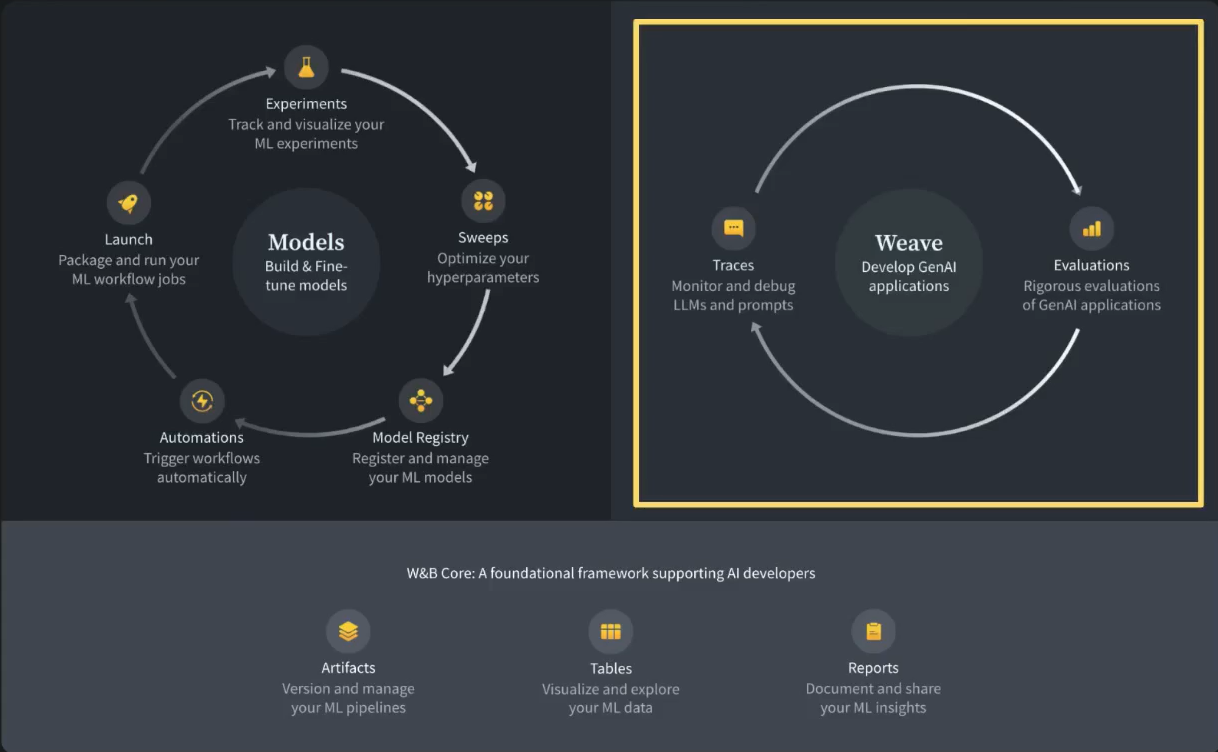
Weave introduces various improvements over traditional model development methods, particularly in applications that require real-time information retrieval.
3.1. Improve Customer Support
Weave-powered systems can more efficiently resolve customer queries by retrieving relevant information in real-time.
3.2. Generate Content
Weave can assist in content generation by pulling external data that ensures content is context-aware and up-to-date.
3.3. Perform Market Research
By retrieving the latest market trends and data, Weave enhances the ability to perform accurate market analysis.
3.4. Support Sales
Weave can support sales by dynamically retrieving information about products, customer needs, and market trends.
3.5. Improve Employee Experience
Weave systems can help enhance employee experience by providing relevant and timely information, aiding decision-making processes.
Leave a Reply